I can't begin to express how awestruck I am in the sheer scope of this project. I've always been a fan of photomosaics and while this is abstraction at the macro level, the micro level is... well, really micro.
From the MIT website:
"We present a visualization of all the nouns in the English language arranged by semantic meaning. Each of the tiles in the mosaic is an arithmetic average of images relating to one of 53,464 nouns."
Their goal is to train computer to "see" better and distinguish objects in photos; you can help to add to the project by doing some community label/tag work on some of the images.
The link to the project is here.
The link to the 3.7Mb jpg image that is the result of the project so far is here. The link to the 3.5Gb tar file containing ALL the images in the project is here.
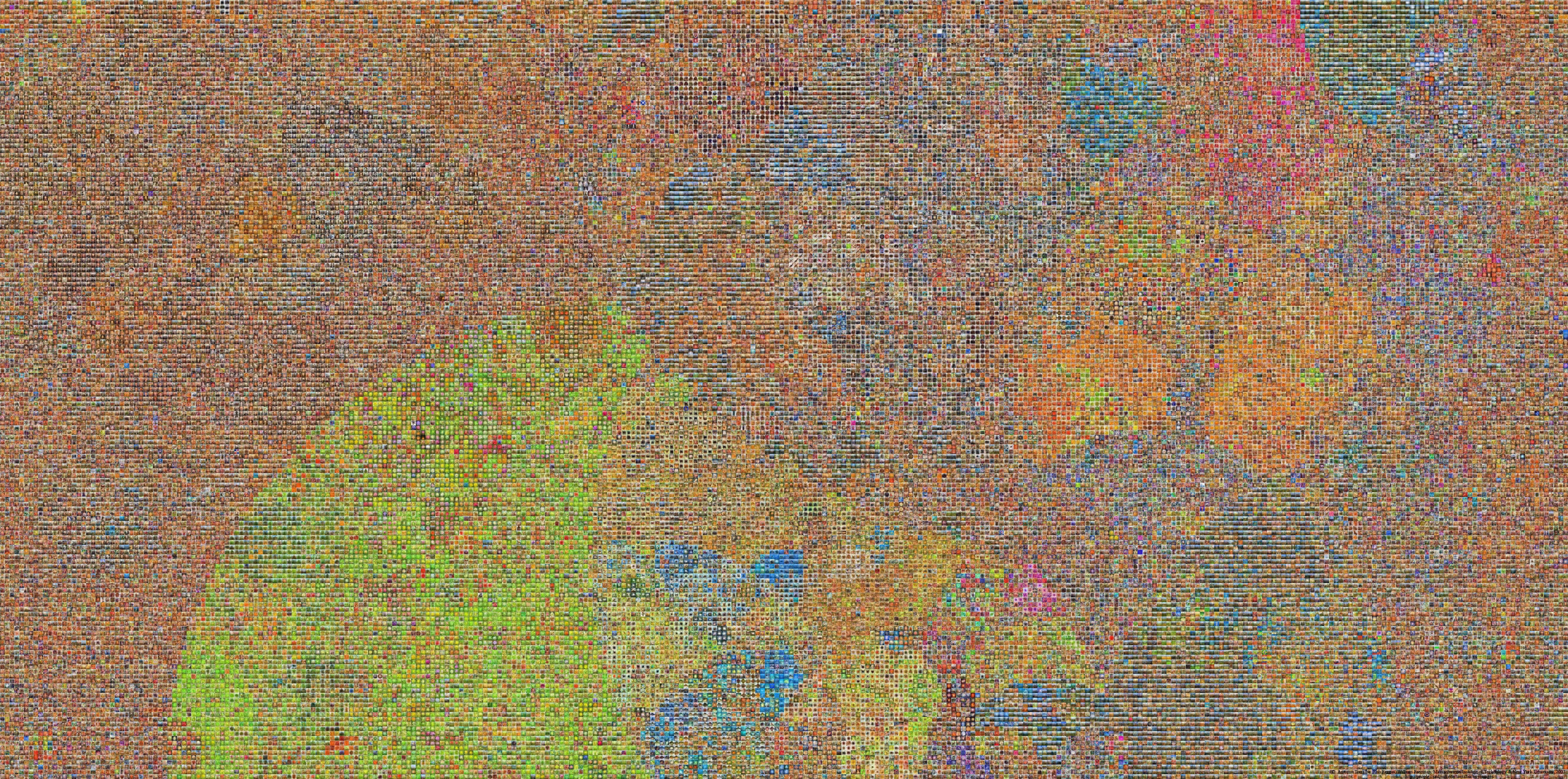{kind=link}
